library(dplyr)
library(haven)
library(labelled)
library(tinytable)
library(readr)
library(here)
library(stringr)
library(lubridate)
library(readxl)
library(ggplot2)
library(scales)
library(tibble)
library(purrr)
library(rvest)
library(psych350data)This post documents the process of collecting and combining data about Superman actors, movie reviews, and box office performance from multiple sources.
Part 1: Superman Actor Data
First, we compile data about the actors who have played Superman and Lois Lane across different films and TV shows.
Load and Process Actor Data
superman_df <- read_excel("superman_raw.xlsx", sheet = "superman")
superman_actors <- superman_df |>
mutate(
clark_birth = ymd(clark_birth),
lois_birth = ymd(lois_birth),
release_date = ymd(release_date),
clark_age = time_length(interval(clark_birth, release_date), "years"),
lois_age = time_length(interval(lois_birth, release_date), "years")
) |>
select(-release_date, -clark_birth, -lois_birth)
numeric_cols <- which(sapply(superman_actors, is.numeric))
superman_actors |>
tt(caption = "Superman and Lois Lane Actors") |>
format_tt(j = numeric_cols, digits = 2) |>
style_tt(bootstrap_class = "table table-striped table-hover")| type | title | year | clark_actor | clark_height | lois_actor | lois_height | clark_age | lois_age |
|---|---|---|---|---|---|---|---|---|
| Film | Superman | 2025 | David Corenswet | 1.9 | Rachel Brosnahan | 1.6 | 32 | 35 |
| Film | Superman: The Movie | 1978 | Christopher Reeve | 1.9 | Margot Kidder | 1.7 | 26 | 30 |
| TV Show | Smallville | 2001 | Tom Welling | 1.9 | Erica Durance | 1.7 | 24 | 23 |
| Film | Superman Returns | 2006 | Brandon Routh | 1.9 | Kate Bosworth | 1.6 | 27 | 23 |
| Film | Superman & the Mole Men | 1951 | George Reeves | 1.9 | Phyllis Coates | 1.6 | 38 | 25 |
| Film | Man of Steel | 2013 | Henry Cavill | 1.9 | Amy Adams | 1.6 | 30 | 39 |
| Serial | Superman | 1948 | Kirk Alyn | 1.9 | Noel Neill | 1.6 | 37 | 27 |
| TV Show | Superman & Lois | 2021 | Tyler Hoechlin | 1.8 | Elizabeth Tulloch | 1.7 | 33 | 40 |
| TV Show | Lois & Clark: The New Adventures of Superman | 1993 | Dean Cain | 1.8 | Teri Hatcher | 1.7 | 27 | 29 |
| TV Show | The Adventures of Superboy | 1988 | John Haymes Newton | 1.8 | NA | NA | 23 | NA |
| TV Show | The Adventures of Superboy | 1989 | Gerard Christopher | 1.8 | NA | NA | 31 | NA |
Create SPSS Version with Labels
For use in statistics classes, we create a properly labeled SPSS file:
superman_data <- superman_actors |>
mutate(
across(where(is.numeric), \(x) if_else(is.na(x), -99, x)),
across(where(is.character), \(x) if_else(is.na(x), "-99", x))
)
# Create value labels for categorical variables
type_values <- unique(superman_data$type)
type_labels <- setNames(seq_along(type_values), type_values)
title_values <- unique(superman_data$title)
title_labels <- setNames(seq_along(title_values), title_values)
actor_values <- unique(superman_data$clark_actor)
actor_values <- actor_values[!is.na(actor_values)]
actor_labels <- setNames(seq_along(actor_values), actor_values)
lois_actor_values <- unique(superman_data$lois_actor)
lois_actor_values <- lois_actor_values[!is.na(lois_actor_values)]
lois_actor_labels <- setNames(seq_along(lois_actor_values), lois_actor_values)
var_labels <- c(
type = "Media Type",
title = "Title of Superman Media",
year = "Year of first superman media appearance",
clark_actor = "Name of actor playing Superman/Clark Kent",
clark_height = "Height of Clark Kent/Superman actor (meters)",
lois_actor = "Name of actress playing Lois Lane",
lois_height = "Height of Lois Lane actress (meters)",
clark_age = "Age of Clark Kent/Superman actor at Release Date",
lois_age = "Age of Lois Lane actress at Release Date"
)
superman_labelled <- superman_data |>
mutate(
type = as.numeric(factor(type, levels = names(type_labels))),
title = as.numeric(factor(title, levels = names(title_labels))),
clark_actor = as.numeric(factor(clark_actor, levels = names(actor_labels))),
lois_actor = as.numeric(factor(lois_actor, levels = names(lois_actor_labels)))
) |>
set_variable_labels(!!!var_labels) |>
set_value_labels(
type = type_labels,
title = title_labels,
clark_actor = actor_labels,
lois_actor = lois_actor_labels
) |>
select(year, title, type, clark_actor, clark_height, clark_age, lois_actor, lois_height, lois_age)
# Set SPSS attributes
for (col in names(superman_labelled)) {
if (col %in% c("type", "title", "clark_actor", "lois_actor")) {
attr(superman_labelled[[col]], "spss_measure") <- "nominal"
attr(superman_labelled[[col]], "spss_format") <- "F8.0"
} else if (col %in% c("year")) {
attr(superman_labelled[[col]], "spss_measure") <- "scale"
attr(superman_labelled[[col]], "spss_format") <- "F4.0"
} else if (col %in% c("clark_height", "lois_height")) {
attr(superman_labelled[[col]], "spss_measure") <- "scale"
attr(superman_labelled[[col]], "spss_format") <- "F4.2"
} else if (col %in% c("clark_age", "lois_age")) {
attr(superman_labelled[[col]], "spss_measure") <- "scale"
attr(superman_labelled[[col]], "spss_format") <- "F5.2"
}
}
attr(superman_labelled, "label") <- "Superman Data"
write_sav(superman_labelled, "superman.sav")
saveRDS(superman_actors, "superman.rds")Part 2: Rotten Tomatoes Data
We scrape critic and audience scores from Rotten Tomatoes for Superman movies.
Scraping Function
scrape_movie <- function(x, ...) {
movie_page <- read_html(
x,
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
)
is_tv <- str_detect(x, "/tv/")
title <- movie_page |>
html_element("title") |>
html_text() |>
str_replace(" \\| Rotten Tomatoes$", "") |>
str_trim()
page_text <- movie_page |> html_text()
critics_score <- page_text |>
str_extract("(\\d+)%\\s*(Avg\\.\\s*)?Tomatometer") |>
str_extract("\\d+") |>
as.numeric()
critics_count <- page_text |>
str_extract("(\\d+)\\s*Reviews") |>
str_extract("\\d+") |>
as.numeric()
critics_status <- NA_character_
if (!is.na(critics_score)) {
if (str_detect(page_text, regex("Certified Fresh", ignore_case = TRUE))) {
critics_status <- "Certified Fresh"
} else if (critics_score >= 60) {
critics_status <- "Fresh"
} else {
critics_status <- "Rotten"
}
}
audience_score <- page_text |>
str_extract("(\\d+)%\\s*(Avg\\.\\s*)?Popcornmeter") |>
str_extract("\\d+") |>
as.numeric()
audience_count_text <- page_text |>
str_extract("([\\d,]+)\\+?\\s*(Verified\\s*)?Ratings")
audience_count <- if (!is.na(audience_count_text)) {
audience_count_text |>
str_extract("[\\d,]+") |>
str_replace_all(",", "") |>
as.numeric()
} else {
NA_real_
}
synopsis <- movie_page |>
html_element('meta[name="description"]') |>
html_attr("content")
poster_url <- movie_page |>
html_element('meta[property="og:image"]') |>
html_attr("content")
tibble(
title = title %||% NA_character_,
critics_score = critics_score %||% NA_real_,
critics_status = critics_status,
critics_count = critics_count %||% NA_real_,
audience_score = audience_score %||% NA_real_,
audience_count = audience_count %||% NA_real_,
synopsis = synopsis %||% NA_character_,
poster_url = poster_url %||% NA_character_,
url = x,
type = if (is_tv) "TV" else "Movie"
)
}Scrape Superman Movies
# Scrape all Superman theatrical films and assign years directly
sm_25_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_2025") |> mutate(year = 2025L)
stm_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_the_movie") |> mutate(year = 1978L)
s2_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_ii") |> mutate(year = 1980L)
s3_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_iii") |> mutate(year = 1983L)
s4_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_iv_the_quest_for_peace") |> mutate(year = 1987L)
sr_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_returns") |> mutate(year = 2006L)
mos_rt <- scrape_movie("https://www.rottentomatoes.com/m/superman_man_of_steel") |> mutate(year = 2013L)
bvs_rt <- scrape_movie("https://www.rottentomatoes.com/m/batman_v_superman_dawn_of_justice") |> mutate(year = 2016L)
# Combine all films - year is already assigned
rt <- bind_rows(
sm_25_rt,
stm_rt,
s2_rt,
s3_rt,
s4_rt,
sr_rt,
mos_rt,
bvs_rt
)
# Check scraped data
rt |>
select(title, year, critics_score, critics_status, audience_score) |>
tt(caption = "Rotten Tomatoes Scores for Superman Films") |>
style_tt(bootstrap_class = "table table-striped table-hover")| title | year | critics_score | critics_status | audience_score |
|---|---|---|---|---|
| Superman (2025) | 2025 | 83 | Certified Fresh | 90 |
| Superman: The Movie | 1978 | 87 | Certified Fresh | 86 |
| Superman II | 1980 | 88 | Certified Fresh | 76 |
| Superman III | 1983 | 31 | Certified Fresh | 23 |
| Superman IV: The Quest for Peace | 1987 | 16 | Certified Fresh | 16 |
| Superman Returns | 2006 | 72 | Certified Fresh | 60 |
| Man of Steel | 2013 | 56 | Certified Fresh | 75 |
| Batman v Superman: Dawn of Justice | 2016 | 28 | Certified Fresh | 63 |
Display RT Data with Posters
rt_display <- rt |>
mutate(
poster = case_when(
is.na(poster_url) | poster_url == "Poster URL not available" ~ "--",
TRUE ~ paste0('<img src="', poster_url, '" height="70">')
),
critics_score_display = if_else(is.na(critics_score), "--", paste0(critics_score, "%")),
audience_score_display = if_else(is.na(audience_score), "--", paste0(audience_score, "%")),
critics_count_display = if_else(is.na(critics_count), "--", as.character(critics_count)),
audience_count_display = if_else(is.na(audience_count), "--", as.character(audience_count)),
critics_status_display = if_else(is.na(critics_status), "--", critics_status)
) |>
select(
poster, title, year,
critics_score_display, critics_status_display, critics_count_display,
audience_score_display, audience_count_display
)
rt_display |>
rename(
Poster = poster,
Title = title,
Year = year,
`Critics Score` = critics_score_display,
`Critics Status` = critics_status_display,
`# Critics Reviews` = critics_count_display,
`Audience Score` = audience_score_display,
`# Audience Ratings` = audience_count_display
) |>
tt() |>
format_tt(escape = FALSE) |>
style_tt(bootstrap_class = "table table-striped table-hover")| Poster | Title | Year | Critics Score | Critics Status | # Critics Reviews | Audience Score | # Audience Ratings |
|---|---|---|---|---|---|---|---|
| Superman (2025) | 2025 | 83% | Certified Fresh | 502 | 90% | 25000 | |
| Superman: The Movie | 1978 | 87% | Certified Fresh | 123 | 86% | 250000 | |
 |
Superman II | 1980 | 88% | Certified Fresh | 113 | 76% | 1e+05 |
| Superman III | 1983 | 31% | Certified Fresh | 103 | 23% | 1e+05 | |
 |
Superman IV: The Quest for Peace | 1987 | 16% | Certified Fresh | 118 | 16% | 50000 |
 |
Superman Returns | 2006 | 72% | Certified Fresh | 290 | 60% | 250000 |
 |
Man of Steel | 2013 | 56% | Certified Fresh | 342 | 75% | 250000 |
| Batman v Superman: Dawn of Justice | 2016 | 28% | Certified Fresh | 437 | 63% | 1e+05 |
Combine RT with Superman Movies Data
# Get the superman_movies data from psych350data
superman_movies <- psych350data::superman_movies
# Year already assigned during scraping, just rename columns
rt_clean <- rt |>
select(
year,
rt_critics_score = critics_score,
rt_critics_status = critics_status,
rt_critics_count = critics_count,
rt_audience_score = audience_score,
rt_audience_count = audience_count
)
# Join with superman_movies by year
superman_rt_combined <- superman_movies |>
left_join(rt_clean, by = join_by(year))
# Check the combined data
superman_rt_combined |>
select(title, year, clark_actor, rt_critics_score, rt_audience_score, rt_critics_status) |>
tt(caption = "Superman Movies with RT Scores") |>
style_tt(bootstrap_class = "table table-striped table-hover")| title | year | clark_actor | rt_critics_score | rt_audience_score | rt_critics_status |
|---|---|---|---|---|---|
| Superman | 2025 | David Corenswet | 83 | 90 | Certified Fresh |
| Superman | 1978 | Christopher Reeve | 87 | 86 | Certified Fresh |
| Man of Steel | 2013 | Henry Cavill | 56 | 75 | Certified Fresh |
| Superman Returns | 2006 | Brandon Routh | 72 | 60 | Certified Fresh |
| Superman II | 1980 | Christopher Reeve | 88 | 76 | Certified Fresh |
| Superman III | 1983 | Christopher Reeve | 31 | 23 | Certified Fresh |
| Superman IV: The Quest for Peace | 1987 | Christopher Reeve | 16 | 16 | Certified Fresh |
| Batman v Superman: Dawn of Justice | 2016 | Henry Cavill | 28 | 63 | Certified Fresh |
Create SPSS Version of RT Data
# Create labelled version for SPSS export
rt_labelled <- rt_clean |>
mutate(
across(where(is.numeric), \(x) if_else(is.na(x), -99, x)),
rt_critics_status = case_when(
rt_critics_status == "Fresh" ~ 1,
rt_critics_status == "Rotten" ~ 2,
rt_critics_status == "Certified Fresh" ~ 3,
TRUE ~ -99
)
)
# Apply value labels
rt_labelled$rt_critics_status <- labelled::labelled(
rt_labelled$rt_critics_status,
labels = c("Fresh" = 1, "Rotten" = 2, "Certified Fresh" = 3)
)
# Apply variable labels
var_labels <- list(
year = "Release year",
rt_critics_score = "Rotten Tomatoes critics score (0-100)",
rt_critics_status = "Rotten Tomatoes critics consensus",
rt_critics_count = "Number of critic reviews",
rt_audience_score = "Rotten Tomatoes audience score (0-100)",
rt_audience_count = "Number of audience ratings"
)
labelled::var_label(rt_labelled) <- var_labels
# Set -99 as missing for numeric columns
numeric_vars <- names(rt_labelled)[sapply(rt_labelled, is.numeric)]
for (var in numeric_vars) {
rt_labelled <- labelled::set_na_values(rt_labelled, !!rlang::sym(var) := -99)
}
write_sav(rt_labelled, "rtomatoes.sav")Part 3: Metacritic Data
We collect critic Metascores and user scores from Metacritic for Superman movies and TV shows.
Why a Lookup Table?
Metacritic uses heavy JavaScript rendering via React/Next.js, making direct HTML scraping with rvest unreliable. The scores are dynamically loaded after the initial page render, so traditional scraping methods fail to capture them consistently.
Instead, we use a manually verified lookup table approach, which provides several advantages: guaranteed accuracy of scores, no dependency on website structure changes, faster execution without HTTP requests, and easy maintenance when scores need updating.
Create Metacritic Dataset
create_metacritic_data <- function() {
tribble(
~title, ~year, ~type, ~metacritic_score, ~user_score, ~metacritic_url,
"Superman", 2025L, "film", 68L, NA_real_, "https://www.metacritic.com/movie/superman-2025/",
"Superman", 1978L, "film", 82L, 8.9, "https://www.metacritic.com/movie/superman/",
"Superman II", 1980L, "film", 83L, 8.3, "https://www.metacritic.com/movie/superman-ii/",
"Superman III", 1983L, "film", 44L, 5.8, "https://www.metacritic.com/movie/superman-iii/",
"Superman IV: The Quest for Peace", 1987L, "film", 24L, 3.8, "https://www.metacritic.com/movie/superman-iv-the-quest-for-peace/",
"Superman Returns", 2006L, "film", 72L, 6.2, "https://www.metacritic.com/movie/superman-returns/",
"Man of Steel", 2013L, "film", 55L, 7.4, "https://www.metacritic.com/movie/man-of-steel/",
"Batman v Superman: Dawn of Justice", 2016L, "film", 44L, 6.3, "https://www.metacritic.com/movie/batman-v-superman-dawn-of-justice/",
"Smallville", 2001L, "tv", 67L, 8.0, "https://www.metacritic.com/tv/smallville/",
"Superman & Lois", 2021L, "tv", 77L, 7.9, "https://www.metacritic.com/tv/superman-lois/",
"Lois & Clark: The New Adventures of Superman", 1993L, "tv", NA_integer_, 7.5, "https://www.metacritic.com/tv/lois-clark-the-new-adventures-of-superman/",
"The Adventures of Superboy", 1988L, "tv", NA_integer_, NA_real_, NA_character_
)
}
metacritic_df <- create_metacritic_data()
# Display the metacritic data
metacritic_df |>
mutate(
metacritic_score = if_else(
is.na(metacritic_score),
"--",
as.character(metacritic_score)
),
user_score = if_else(
is.na(user_score),
"--",
format(user_score, nsmall = 1)
)
) |>
select(title, year, type, metacritic_score, user_score) |>
tt(caption = "Metacritic Scores for Superman Media") |>
style_tt(bootstrap_class = "table table-striped table-hover")| title | year | type | metacritic_score | user_score |
|---|---|---|---|---|
| Superman | 2025 | film | 68 | -- |
| Superman | 1978 | film | 82 | 8.9 |
| Superman II | 1980 | film | 83 | 8.3 |
| Superman III | 1983 | film | 44 | 5.8 |
| Superman IV: The Quest for Peace | 1987 | film | 24 | 3.8 |
| Superman Returns | 2006 | film | 72 | 6.2 |
| Man of Steel | 2013 | film | 55 | 7.4 |
| Batman v Superman: Dawn of Justice | 2016 | film | 44 | 6.3 |
| Smallville | 2001 | tv | 67 | 8.0 |
| Superman & Lois | 2021 | tv | 77 | 7.9 |
| Lois & Clark: The New Adventures of Superman | 1993 | tv | -- | 7.5 |
| The Adventures of Superboy | 1988 | tv | -- | -- |
Metacritic Score Interpretation
Metacritic uses a weighted average of critic reviews to create a Metascore on a 0-100 scale:
- 81-100: Universal Acclaim
- 61-80: Generally Favorable
- 40-60: Mixed or Average
- 20-39: Generally Unfavorable
- 0-19: Overwhelming Dislike
The user score is a simple average of user ratings on a 0-10 scale.
Create SPSS Version of Metacritic Data
export_metacritic_spss <- function(metacritic_df, output_path = "metacritic.sav") {
# Prepare data with -99 for missing values (SPSS convention)
metacritic_spss <- metacritic_df |>
mutate(
across(where(is.numeric), \(x) if_else(is.na(x), -99, as.numeric(x))),
across(where(is.character), \(x) if_else(is.na(x), "-99", x))
)
# Create value labels for categorical variables
title_values <- unique(metacritic_df$title)
title_labels <- setNames(seq_along(title_values), title_values)
type_labels <- c("film" = 1, "tv" = 2)
# Define variable labels
var_labels <- list(
title = "Title of Superman movie/TV show",
year = "Year of release/premiere",
type = "Media type (1=film, 2=tv)",
metacritic_score = "Metacritic critic score (0-100, -99=missing)",
user_score = "Metacritic user score (0-10, -99=missing)",
metacritic_url = "URL to Metacritic page"
)
# Convert to numeric codes and apply labels
metacritic_labelled <- metacritic_spss |>
mutate(
title = as.numeric(factor(title, levels = names(title_labels))),
type = as.numeric(factor(type, levels = names(type_labels)))
) |>
set_variable_labels(!!!var_labels) |>
set_value_labels(
title = title_labels,
type = type_labels
)
# Set SPSS-specific attributes
for (col in names(metacritic_labelled)) {
if (col %in% c("title", "type")) {
attr(metacritic_labelled[[col]], "spss_measure") <- "nominal"
attr(metacritic_labelled[[col]], "spss_format") <- "F8.0"
} else if (col == "year") {
attr(metacritic_labelled[[col]], "spss_measure") <- "scale"
attr(metacritic_labelled[[col]], "spss_format") <- "F4.0"
} else if (col == "metacritic_score") {
attr(metacritic_labelled[[col]], "spss_measure") <- "scale"
attr(metacritic_labelled[[col]], "spss_format") <- "F3.0"
} else if (col == "user_score") {
attr(metacritic_labelled[[col]], "spss_measure") <- "scale"
attr(metacritic_labelled[[col]], "spss_format") <- "F4.1"
}
}
attr(metacritic_labelled, "label") <- "Metacritic Superman Scores"
write_sav(metacritic_labelled, output_path)
message("Exported Metacritic data to: ", output_path)
invisible(metacritic_labelled)
}
export_metacritic_spss(metacritic_df)Part 4: Box Office Data
We scrape box office performance data from Box Office Mojo.
Find Movie IDs
find_movie_id <- function(movie_title) {
search_term <- gsub(" ", "+", movie_title)
search_url <- paste0("https://www.boxofficemojo.com/search/?q=", search_term)
search_page <- rvest::read_html(search_url)
search_results <- search_page |>
rvest::html_nodes("a.a-size-medium.a-link-normal.a-text-bold")
result_links <- rvest::html_attr(search_results, "href")
result_titles <- rvest::html_text(search_results)
results_df <- data.frame(
title = result_titles,
link = result_links,
stringsAsFactors = FALSE
)
results_df$movie_id <- stringr::str_extract(results_df$link, "tt[0-9]+")
results_df
}
superman_list <- find_movie_id("Superman")
superman_list |> tt()Box Office Mojo Scraping Function
extract_complete_movie_data <- function(movie_id) {
url <- paste0("https://www.boxofficemojo.com/title/", movie_id, "/")
page <- read_html(url)
movie_data <- data.frame(movie_id = movie_id, stringsAsFactors = FALSE)
# Extract movie summary info box
summary_box <- page |> html_node(".a-section.mojo-summary")
if (!is.na(summary_box)) {
title_element <- summary_box |> html_node("h1.a-size-extra-large")
if (!is.na(title_element)) {
full_title <- html_text(title_element) |> str_trim()
main_title <- str_replace(full_title, "\\s*\\(\\d{4}\\)$", "")
year <- str_extract(full_title, "\\(\\d{4}\\)") |>
str_replace_all("[\\(\\)]", "")
movie_data$title <- main_title
movie_data$year <- year
}
description <- summary_box |>
html_node("span.a-size-medium") |>
html_text() |>
str_trim()
if (!is.na(description)) {
movie_data$description <- description
}
img_element <- summary_box |> html_node("img")
if (!is.na(img_element)) {
movie_data$poster_url <- html_attr(img_element, "src")
img_hires <- html_attr(img_element, "data-a-hires")
if (!is.na(img_hires)) {
movie_data$poster_url_hires <- img_hires
}
}
}
# Extract box office summary table data
summary_section <- page |>
html_node(".a-section.a-spacing-none.mojo-summary-table")
if (!is.na(summary_section)) {
data_sections <- summary_section |>
html_nodes(".a-section.a-spacing-none")
for (section in data_sections) {
if (length(xml_find_first(section, ".//span[@class='a-size-small']")) == 0) {
next
}
category <- section |>
html_node(".a-size-small") |>
html_text() |>
str_trim() |>
str_replace_all("\\s*\\([^)]*\\)\\s*", "") |>
str_trim()
money_node <- section |> html_node("span.money")
money_value <- if (!is.na(money_node)) html_text(money_node) else NA
percent_node <- section |> html_node("span.percent")
percent <- if (!is.na(percent_node)) html_text(percent_node) else NA
if (!is.na(money_value)) {
clean_money <- gsub("[$,]", "", money_value)
numeric_money <- as.numeric(clean_money)
category_clean <- tolower(str_replace_all(category, "[^[:alnum:]]", "_"))
category_clean <- str_replace_all(category_clean, "_+", "_")
category_clean <- str_remove(category_clean, "_$")
movie_data[[paste0(category_clean, "_gross")]] <- money_value
movie_data[[paste0(category_clean, "_gross_numeric")]] <- numeric_money
if (!is.na(percent)) {
movie_data[[paste0(category_clean, "_percent")]] <- percent
percent_numeric <- as.numeric(gsub("[%]", "", percent))
movie_data[[paste0(category_clean, "_percent_numeric")]] <- percent_numeric
}
}
}
}
movie_data
}Extract Multiple Movies
extract_multiple_movies <- function(movie_ids) {
all_data <- NULL
for (id in movie_ids) {
cat("Processing movie ID:", id, "\n")
tryCatch({
movie_data <- extract_complete_movie_data(id)
if (is.null(all_data)) {
all_data <- movie_data
} else {
# Handle different columns
missing_cols <- setdiff(names(all_data), names(movie_data))
for (col in missing_cols) movie_data[[col]] <- NA
missing_cols <- setdiff(names(movie_data), names(all_data))
for (col in missing_cols) all_data[[col]] <- NA
all_data <- bind_rows(all_data, movie_data)
}
}, error = function(e) {
cat("Error processing movie ID:", id, "- Error:", e$message, "\n")
})
Sys.sleep(2) # Be polite to the server
}
all_data
}
# Superman movie IDs from IMDB/Box Office Mojo
movie_ids <- c(
"tt5950044",
"tt0078346",
"tt0770828",
"tt0348150",
"tt0081573",
"tt0086393",
"tt0094074",
"tt2975590"
)
all_movies <- extract_multiple_movies(movie_ids)
# Display results
all_movies |>
mutate(
poster = if_else(
!is.na(poster_url),
paste0('<img src="', poster_url, '" height="80">'),
""
)
) |>
select(poster, title, year, worldwide_gross, budget) |>
tt() |>
format_tt(escape = FALSE) |>
style_tt(bootstrap_class = "table table-striped")Clean Box Office Data
clean_boxoffice_df <- all_movies |>
mutate(
year = as.numeric(year),
box_office_numeric = worldwide_gross_numeric,
budget_numeric = as.numeric(budget_numeric),
opening = as.numeric(domestic_opening_numeric),
domestic = as.numeric(domestic_gross_numeric),
percent = as.numeric(domestic_percent_numeric),
title = str_trim(title),
release_date = str_extract(earliest_release_date, "\\w+ \\d+, \\d{4}"),
release_date = as.Date(release_date, format = "%B %d, %Y"),
decade = paste0(floor(year / 10) * 10, "s"),
mpaa_rating = str_trim(mpaa),
mpaa_rating = if_else(is.na(mpaa_rating), "Unrated", mpaa_rating),
is_original_series = year >= 1978 & year <= 1987,
is_modern_era = year == 2006,
is_dceu = year >= 2010 & year <= 2024,
is_dcu = year >= 2025,
clark_actor = case_when(
is_original_series ~ "Christopher Reeve",
is_modern_era ~ "Brandon Routh",
is_dceu ~ "Henry Cavill",
is_dcu ~ "David Corenswet"
)
) |>
select(
movie_id, title, year, release_date, decade, mpaa_rating,
budget_numeric, box_office_numeric, opening, domestic, percent,
is_original_series, is_modern_era, is_dceu, is_dcu, clark_actor,
poster_url_hires
)
write.csv(clean_boxoffice_df, "boxoffice_raw.csv", row.names = FALSE)
write_sav(boxoffice_labelled, "boxoffice.sav")Part 5: Letterboxd Reviews
We also scrape user reviews from Letterboxd for sentiment analysis.
Letterboxd Scraping Function
# Source the letterboxd scraping functions
source("letterbox.R")
safe_scrape <- function(movie_slug, num_pages = 2, random_pages = TRUE, max_page = 5) {
tryCatch({
result <- scrape_movie_reviews(
movie_slug,
num_pages = num_pages,
random_pages = random_pages,
max_page = max_page,
file = FALSE
)
if (is.null(result) || nrow(result) == 0) {
message("No data returned for: ", movie_slug)
return(NULL)
}
result
}, error = function(e) {
message("Error scraping ", movie_slug, ": ", e$message)
NULL
})
}
# Scrape reviews for each movie
superman_1948 <- safe_scrape("superman-1948", max_page = 5)
atomman <- safe_scrape("atom-man-vs-superman", max_page = 10)
moleman <- safe_scrape("superman-and-the-mole-men", max_page = 10)
superman2025 <- safe_scrape("superman-2025", max_page = 50)
superman1 <- safe_scrape("superman", max_page = 50)
superman2 <- safe_scrape("superman-ii", max_page = 50)
superman3 <- safe_scrape("superman-iii", max_page = 50)
superman4 <- safe_scrape("superman-iv-the-quest-for-peace", max_page = 50)
superman_returns <- safe_scrape("superman-returns", max_page = 50)
man_of_steel <- safe_scrape("man-of-steel", max_page = 50)
# Combine all results
all_scrapes <- list(
superman_1948, atomman, moleman, superman1,
superman_returns, man_of_steel, superman2025
)
valid_scrapes <- Filter(Negate(is.null), all_scrapes)
if (length(valid_scrapes) > 0) {
letterboxd <- valid_scrapes |>
list_rbind() |>
rename(title = movie_title)
message("Successfully scraped ", nrow(letterboxd), " reviews")
}Part 6: Combined Dataset
Finally, we combine all data sources into a single comprehensive dataset.
Export Combined Superman Data
# Create data directory if it doesn't exist
if (!dir.exists(here("data"))) {
dir.create(here("data"), recursive = TRUE)
}
# Join RT data with full superman_movies data
superman_combined <- superman_movies |>
left_join(rt_clean, by = join_by(year)) |>
mutate(
# Create tomatometer variable (Fresh/Rotten binary)
tomatometer = case_when(
rt_critics_score >= 60 ~ "Fresh",
rt_critics_score < 60 ~ "Rotten",
TRUE ~ NA_character_
)
)
# Display final combined dataset
superman_combined |>
select(
title, year, clark_actor,
budget, worldwide_gross, budget_cat, box_office_cat,
rt_critics_score, rt_audience_score, tomatometer
) |>
tt(caption = "Combined Superman Movies Dataset") |>
style_tt(bootstrap_class = "table table-striped table-hover")| title | year | clark_actor | budget | worldwide_gross | budget_cat | box_office_cat | rt_critics_score | rt_audience_score | tomatometer |
|---|---|---|---|---|---|---|---|---|---|
| Superman | 2025 | David Corenswet | NA | NA | NA | NA | 83 | 90 | Fresh |
| Superman | 1978 | Christopher Reeve | 55 | 300.47845 | Medium | Medium | 87 | 86 | Fresh |
| Man of Steel | 2013 | Henry Cavill | 225 | 670.14552 | High | High | 56 | 75 | Rotten |
| Superman Returns | 2006 | Brandon Routh | 270 | 391.08119 | High | Medium | 72 | 60 | Fresh |
| Superman II | 1980 | Christopher Reeve | 54 | 216.38571 | Medium | Medium | 88 | 76 | Fresh |
| Superman III | 1983 | Christopher Reeve | NA | 80.25062 | NA | Low | 31 | 23 | Rotten |
| Superman IV: The Quest for Peace | 1987 | Christopher Reeve | 17 | 30.28102 | Low | Low | 16 | 16 | Rotten |
| Batman v Superman: Dawn of Justice | 2016 | Henry Cavill | 250 | 874.36280 | High | High | 28 | 63 | Rotten |
Save Combined Data
# Save as RDS for use in psych350data package
saveRDS(superman_combined, here("data", "superman_combined.rds"))
# Also export directly to SPSS for immediate use
superman_spss <- superman_combined |>
mutate(
across(where(is.numeric), \(x) if_else(is.na(x), -99, x)),
across(where(is.character), \(x) if_else(is.na(x) | x == "", "-99", x))
)
write_sav(superman_spss, here("data", "superman_combined.sav"))
cat("Saved superman_combined.rds and superman_combined.sav\n")
cat("Dimensions:", nrow(superman_combined), "rows x", ncol(superman_combined), "columns\n")Summary Statistics
# Summary of the combined dataset
superman_combined |>
summarise(
n_films = n(),
n_with_rt = sum(!is.na(rt_critics_score)),
mean_critics = mean(rt_critics_score, na.rm = TRUE),
mean_audience = mean(rt_audience_score, na.rm = TRUE),
n_fresh = sum(tomatometer == "Fresh", na.rm = TRUE),
n_rotten = sum(tomatometer == "Rotten", na.rm = TRUE)
) |>
tt(caption = "Summary Statistics") |>
style_tt(bootstrap_class = "table table-striped")| n_films | n_with_rt | mean_critics | mean_audience | n_fresh | n_rotten |
|---|---|---|---|---|---|
| 8 | 8 | 57.625 | 61.125 | 4 | 4 |
# Cross-tab for chi-square preview
superman_combined |>
filter(!is.na(budget_cat) & !is.na(tomatometer)) |>
count(budget_cat, tomatometer) |>
tt(caption = "Budget Category × Tomatometer Cross-tabulation") |>
style_tt(bootstrap_class = "table table-striped")| budget_cat | tomatometer | n |
|---|---|---|
| High | Fresh | 1 |
| High | Rotten | 2 |
| Low | Rotten | 1 |
| Medium | Fresh | 2 |
Combine with Metacritic Data
combine_with_metacritic <- function(superman_df, metacritic_df) {
# Perform the join using year for disambiguation
superman_df |>
left_join(
metacritic_df |>
filter(type == "film") |>
select(year, metacritic_score, user_score, metacritic_url),
by = join_by(year)
)
}
# Combine with existing superman_combined data
superman_with_metacritic <- superman_combined |>
combine_with_metacritic(metacritic_df)
# Display combined data
superman_with_metacritic |>
select(title, year, clark_actor, rt_critics_score, metacritic_score, user_score) |>
tt(caption = "Superman Films with RT and Metacritic Scores") |>
style_tt(bootstrap_class = "table table-striped table-hover")
# Save the complete dataset
saveRDS(superman_with_metacritic, here("data", "superman_with_metacritic.rds"))Part 7: Visualizations
Superman Actor Heights Over Time
ggplot(superman_actors |> filter(!is.na(clark_height)),
aes(x = year, y = clark_height)) +
geom_point(aes(color = type), size = 5, alpha = 0.8) +
geom_text(
aes(label = clark_actor, color = type),
hjust = -0.1,
vjust = 0.5,
size = 3.5,
fontface = "bold",
show.legend = FALSE
) +
scale_color_manual(
values = c("film" = "#0073CF", "tv" = "#E21A22"),
labels = c("Film", "TV Show")
) +
labs(
title = "Superman Actor Heights Over Time",
subtitle = "Height in meters by year of first appearance",
x = "Year",
y = "Height (m)",
color = "Media Type"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
) +
scale_x_continuous(breaks = seq(1950, 2030, by = 10)) +
scale_y_continuous(limits = c(1.75, 2.05)) +
coord_cartesian(clip = "off")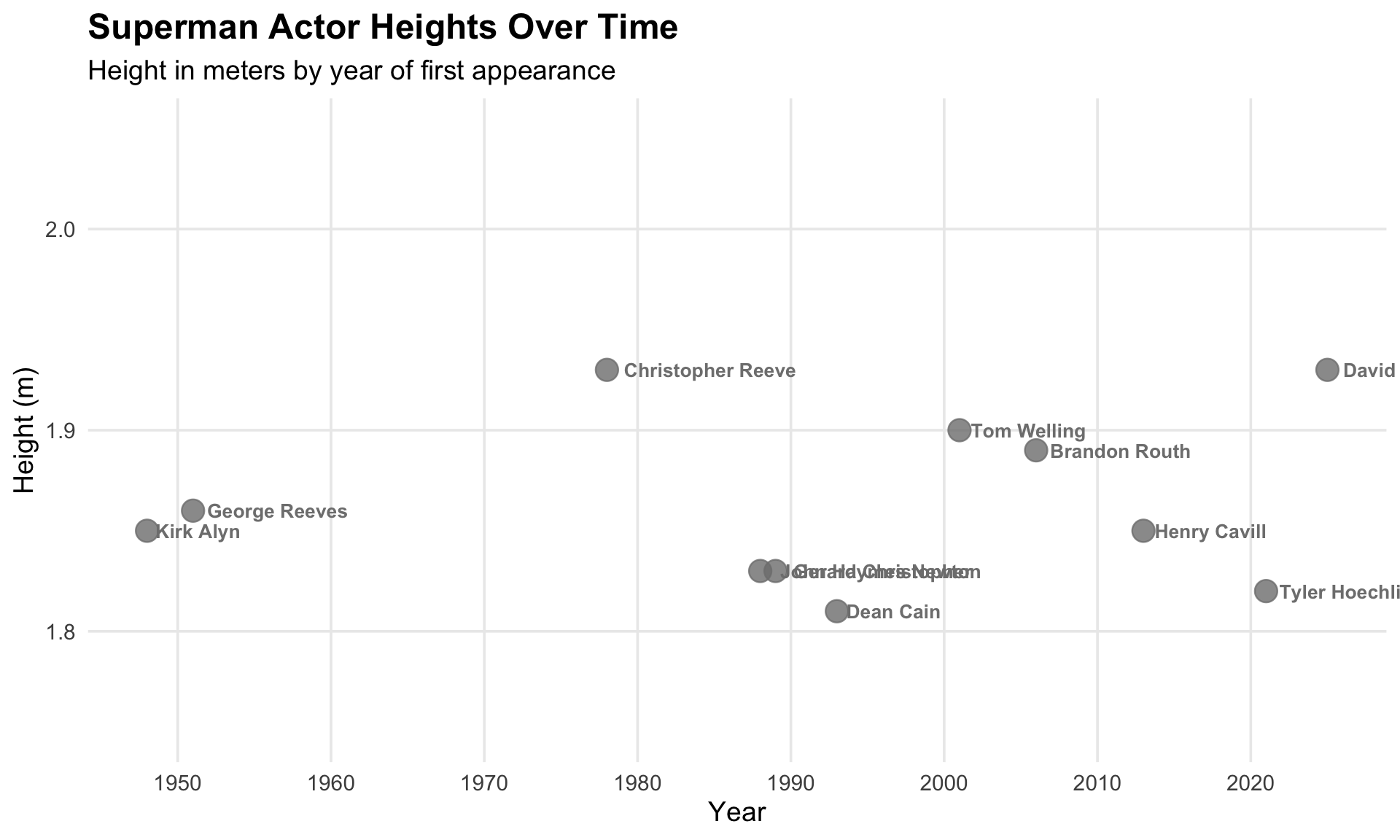
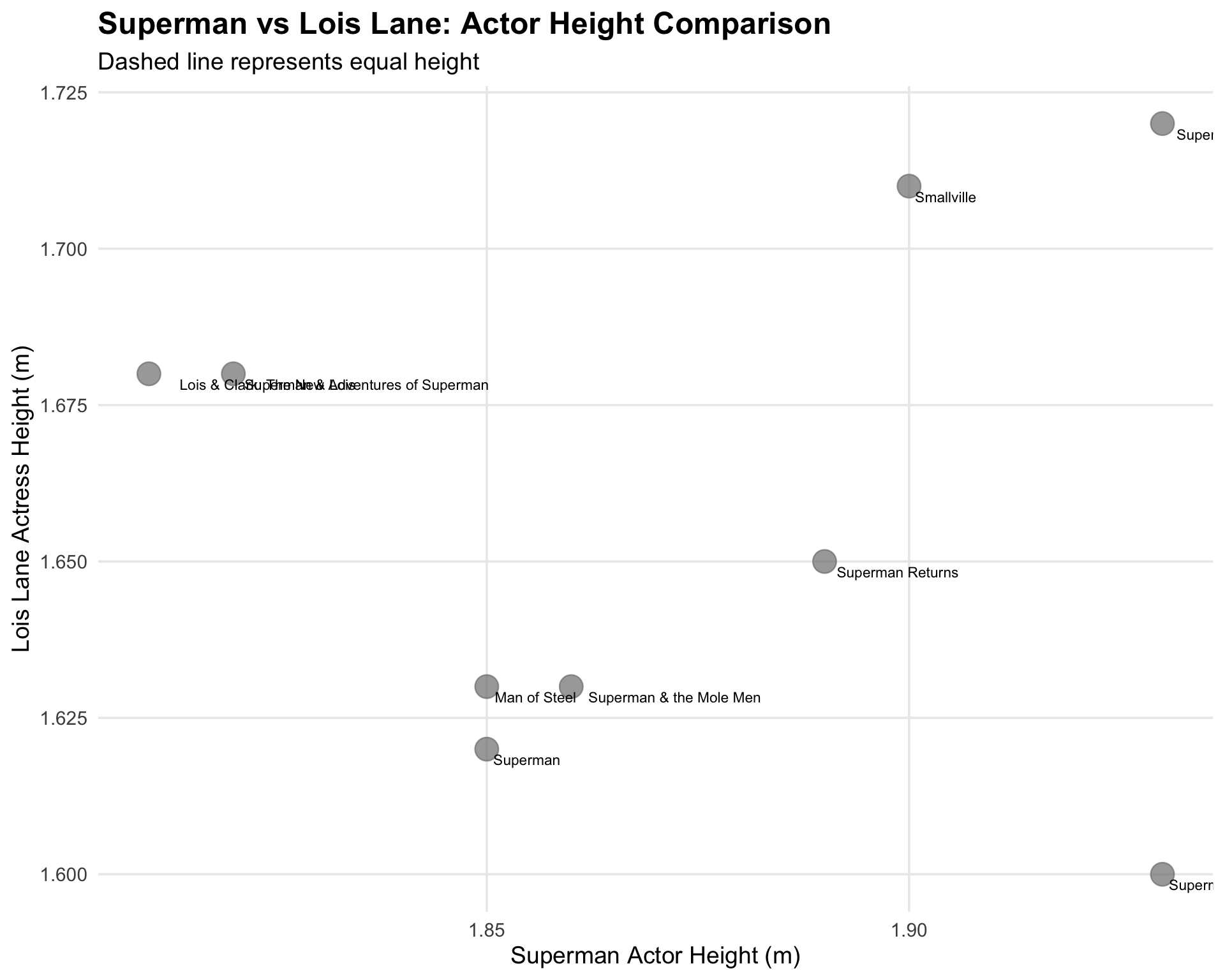
Height Comparison: Superman vs Lois Lane
superman_actors |>
filter(!is.na(lois_height) & !is.na(clark_height)) |>
ggplot(aes(x = clark_height, y = lois_height)) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", alpha = 0.3) +
geom_point(aes(color = type), size = 6, alpha = 0.7) +
geom_text(
aes(label = title),
hjust = -0.1,
vjust = 1.5,
size = 3
) +
scale_color_manual(
values = c("film" = "#0073CF", "tv" = "#E21A22"),
labels = c("Film", "TV Show")
) +
labs(
title = "Superman vs Lois Lane: Actor Height Comparison",
subtitle = "Dashed line represents equal height",
x = "Superman Actor Height (m)",
y = "Lois Lane Actress Height (m)",
color = "Media Type"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
)
Age Comparison: Superman vs Lois Lane
superman_actors |>
filter(!is.na(lois_age) & !is.na(clark_age)) |>
ggplot(aes(x = clark_age, y = lois_age)) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", alpha = 0.3) +
geom_point(aes(color = type), size = 6, alpha = 0.7) +
geom_text(
aes(label = clark_actor),
hjust = -0.1,
vjust = 1.5,
size = 3
) +
scale_color_manual(
values = c("film" = "#0073CF", "tv" = "#E21A22"),
labels = c("Film", "TV Show")
) +
labs(
title = "Superman vs Lois Lane: Actor Age Comparison",
subtitle = "Age at time of release; dashed line represents equal age",
x = "Superman Actor Age (years)",
y = "Lois Lane Actress Age (years)",
color = "Media Type"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
) +
xlim(20, 45) +
ylim(20, 45)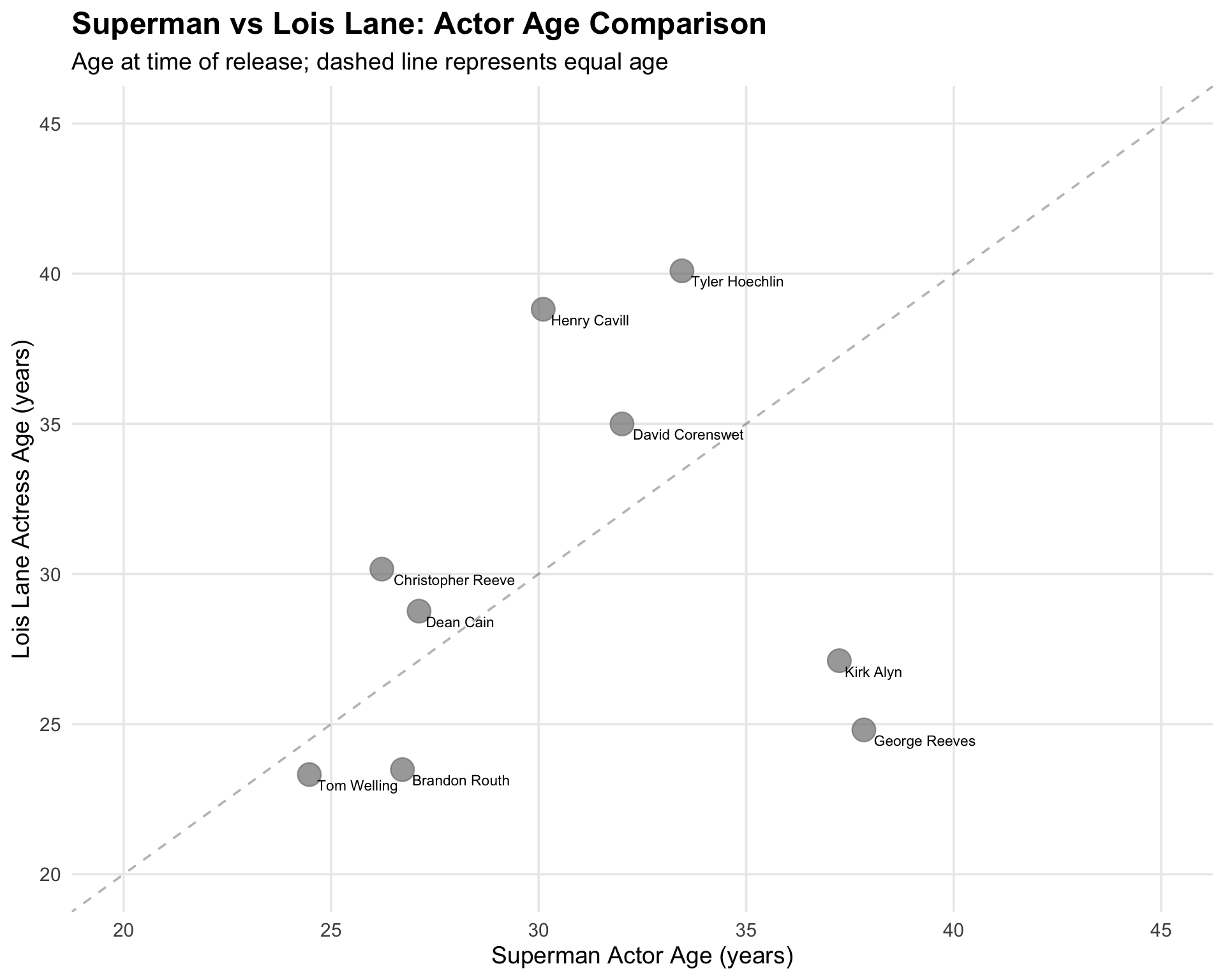
Metacritic Scores Over Time
metacritic_df |>
filter(!is.na(metacritic_score)) |>
ggplot(aes(x = year, y = metacritic_score, color = type)) +
geom_hline(yintercept = 61, linetype = "dashed", alpha = 0.4, color = "darkgreen") +
geom_hline(yintercept = 40, linetype = "dashed", alpha = 0.4, color = "goldenrod") +
annotate(
"text", x = 1982, y = 64,
label = "Generally Favorable",
size = 3, alpha = 0.6, color = "darkgreen"
) +
annotate(
"text", x = 1982, y = 37,
label = "Mixed/Average",
size = 3, alpha = 0.6, color = "goldenrod"
) +
geom_point(size = 6, alpha = 0.8) +
geom_text(
aes(label = title),
hjust = -0.08,
vjust = 0.5,
size = 3.2,
fontface = "bold",
show.legend = FALSE
) +
scale_color_manual(
values = c("film" = "#0073CF", "tv" = "#E21A22"),
labels = c("Film", "TV Show")
) +
scale_y_continuous(
limits = c(0, 100),
breaks = seq(0, 100, 20),
expand = expansion(mult = c(0.02, 0.02))
) +
scale_x_continuous(
breaks = seq(1980, 2030, 10),
limits = c(1975, 2035)
) +
labs(
title = "Metacritic Scores for Superman Media Over Time",
subtitle = "Critic Metascores (0-100 scale); dashed lines indicate review thresholds",
x = "Year",
y = "Metacritic Score",
color = "Media Type",
caption = "Source: metacritic.com | Scores as of February 2026"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold", size = 18),
plot.subtitle = element_text(color = "gray40"),
plot.caption = element_text(color = "gray50", size = 9),
panel.grid.minor = element_blank()
) +
coord_cartesian(clip = "off")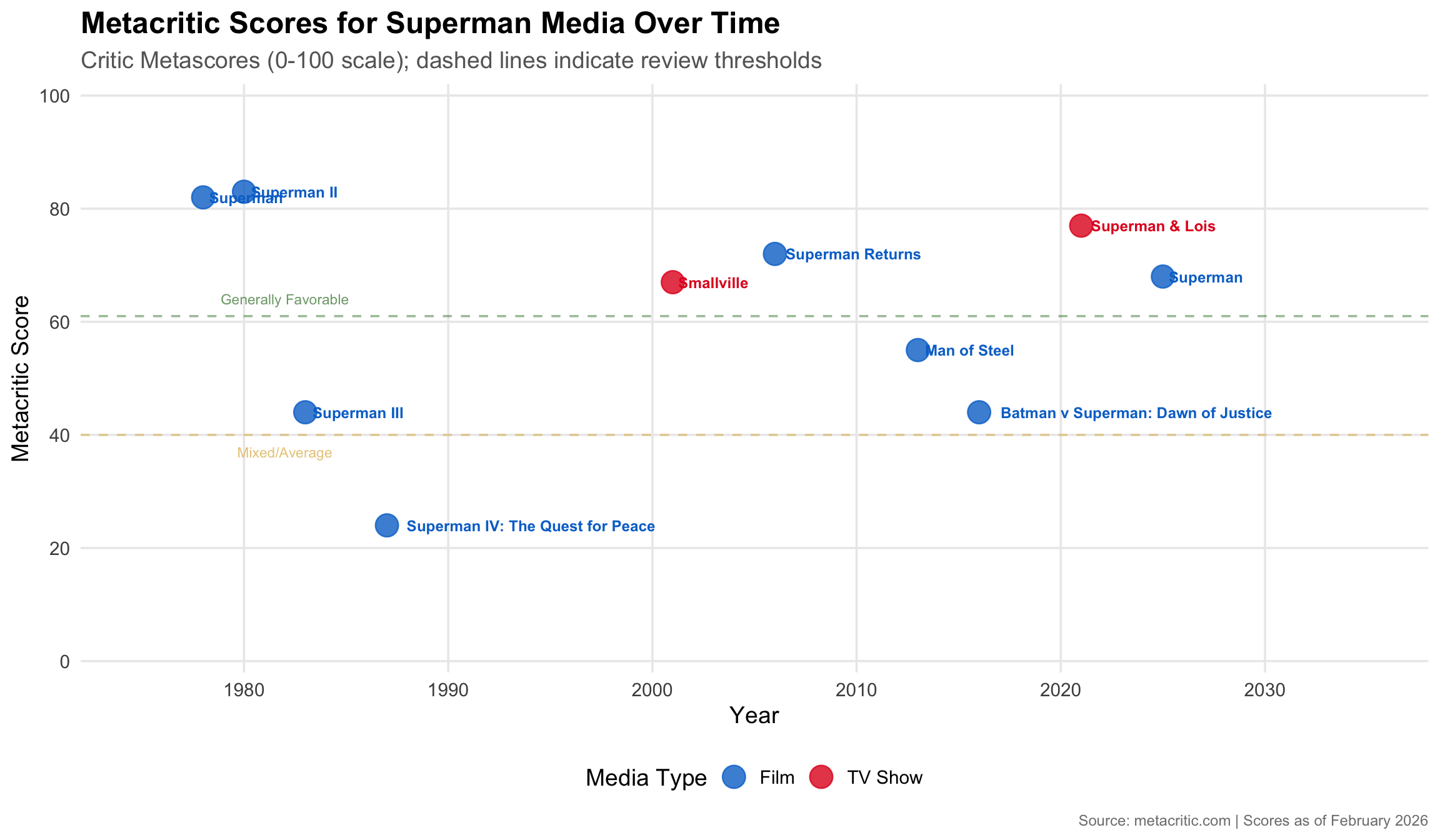
Critics vs User Scores Comparison
metacritic_df |>
filter(!is.na(metacritic_score) & !is.na(user_score)) |>
mutate(
# Convert user score to 0-100 scale for comparison
user_score_scaled = user_score * 10,
score_diff = user_score_scaled - metacritic_score,
diff_label = case_when(
score_diff > 10 ~ "Users higher",
score_diff < -10 ~ "Critics higher",
TRUE ~ "Similar"
)
) |>
ggplot(aes(x = metacritic_score, y = user_score_scaled)) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", alpha = 0.3) +
geom_point(aes(color = type, shape = diff_label), size = 5, alpha = 0.8) +
geom_text(
aes(label = paste0(title, " (", year, ")")),
hjust = -0.1,
vjust = 1.5,
size = 2.8
) +
scale_color_manual(
values = c("film" = "#0073CF", "tv" = "#E21A22"),
labels = c("Film", "TV Show")
) +
scale_shape_manual(
values = c("Users higher" = 17, "Critics higher" = 15, "Similar" = 16)
) +
labs(
title = "Metacritic: Critics vs User Scores",
subtitle = "User scores scaled to 0-100; dashed line indicates agreement",
x = "Critic Metascore (0-100)",
y = "User Score (scaled to 0-100)",
color = "Media Type",
shape = "Score Difference"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
legend.box = "vertical",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
) +
xlim(20, 100) +
ylim(20, 100)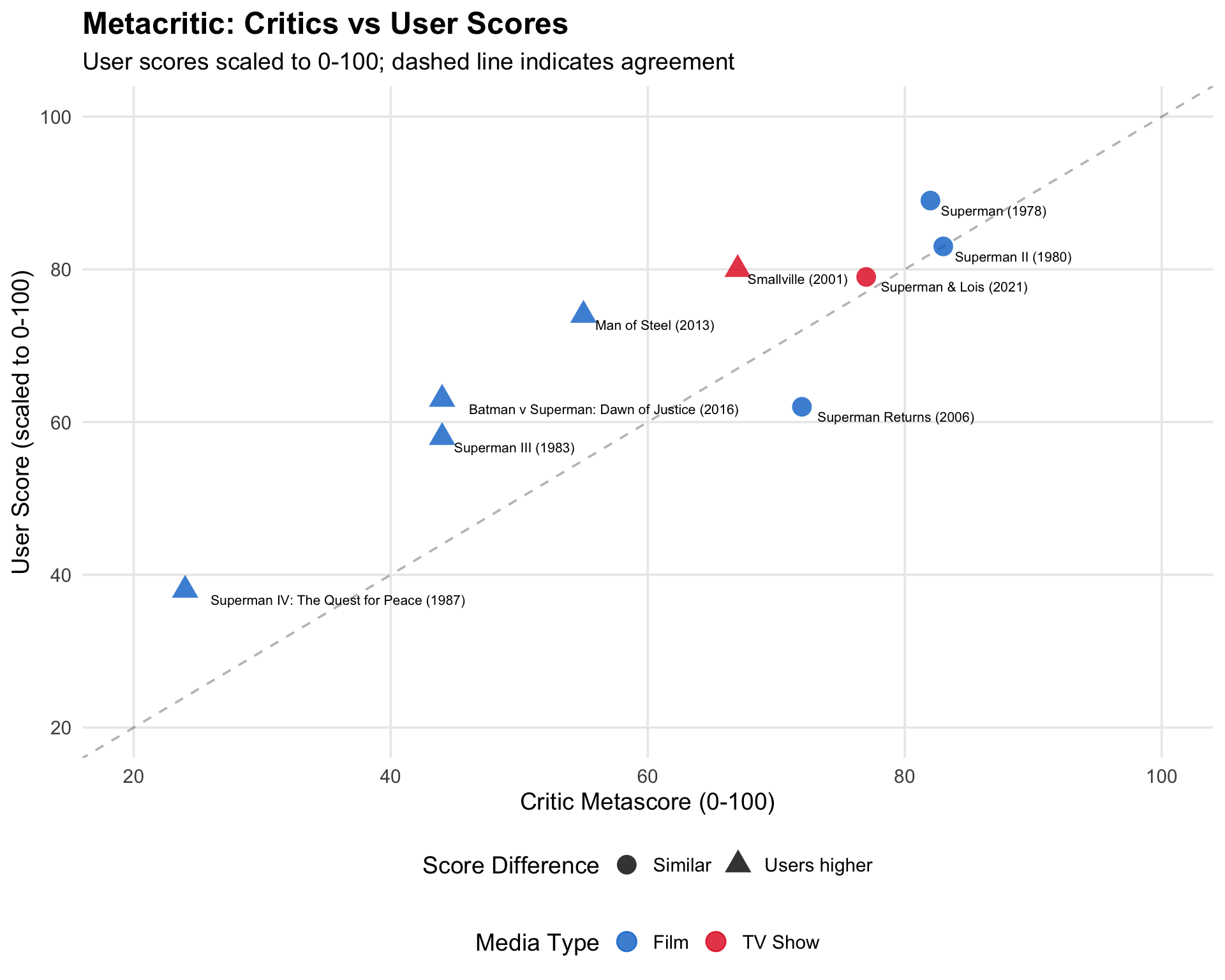
RT Scores: Critics vs Audience
superman_combined |>
filter(!is.na(rt_critics_score) & !is.na(rt_audience_score)) |>
mutate(
score_diff = rt_audience_score - rt_critics_score,
diff_label = case_when(
score_diff > 10 ~ "Audience higher",
score_diff < -10 ~ "Critics higher",
TRUE ~ "Similar"
)
) |>
ggplot(aes(x = rt_critics_score, y = rt_audience_score)) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", alpha = 0.3) +
geom_point(aes(color = tomatometer, shape = diff_label), size = 6, alpha = 0.8) +
geom_text(
aes(label = paste0(title, " (", year, ")")),
hjust = -0.1,
vjust = 1.5,
size = 3
) +
scale_color_manual(
values = c("Fresh" = "darkgreen", "Rotten" = "red3"),
labels = c("Fresh (≥60%)", "Rotten (<60%)")
) +
scale_shape_manual(
values = c("Audience higher" = 17, "Critics higher" = 15, "Similar" = 16)
) +
labs(
title = "Rotten Tomatoes: Critics vs Audience Scores",
subtitle = "Dashed line indicates perfect agreement between critics and audience",
x = "Critics Score (%)",
y = "Audience Score (%)",
color = "Tomatometer",
shape = "Score Difference"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "bottom",
legend.box = "vertical",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
) +
xlim(0, 100) +
ylim(0, 100) +
coord_cartesian(clip = "off")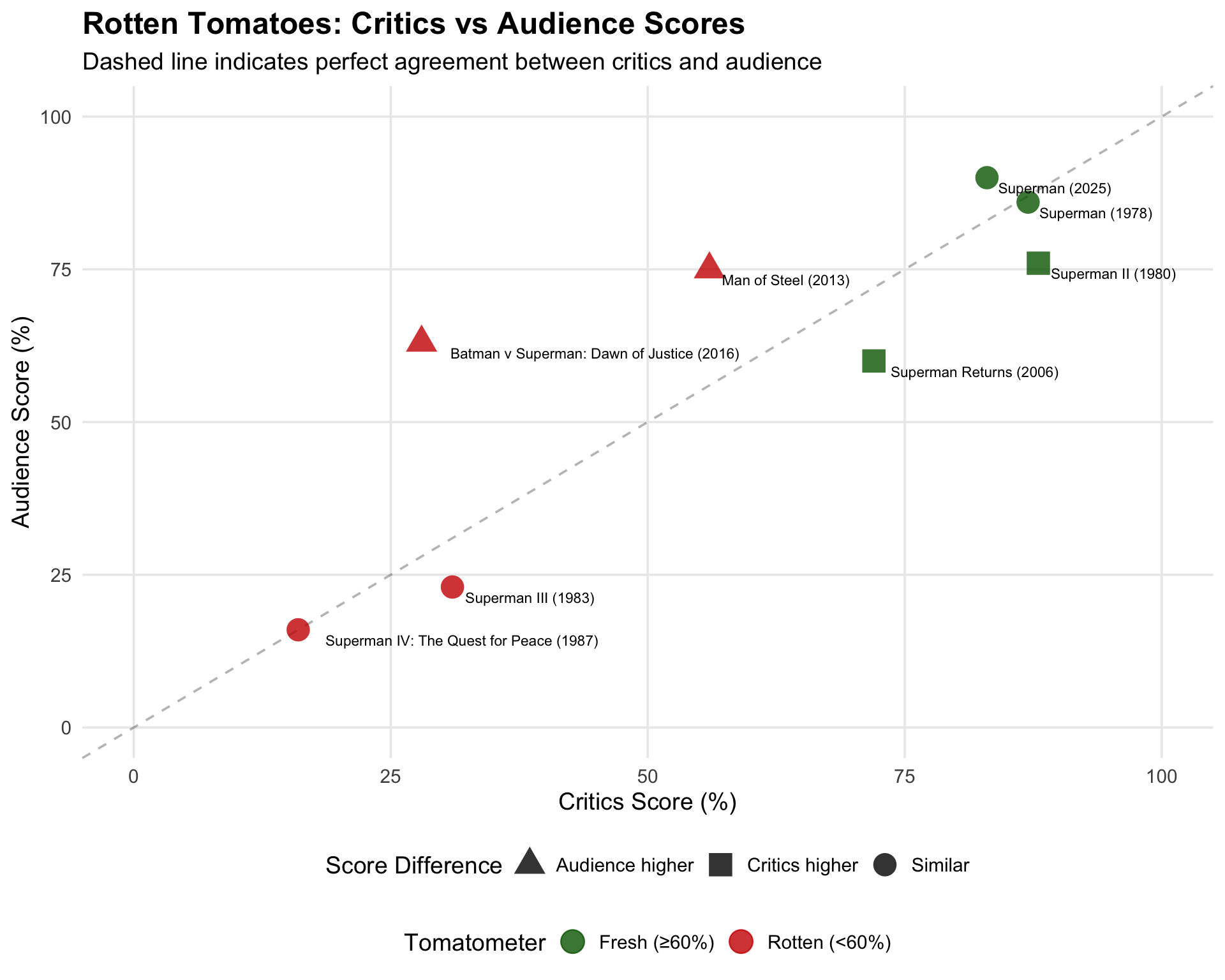
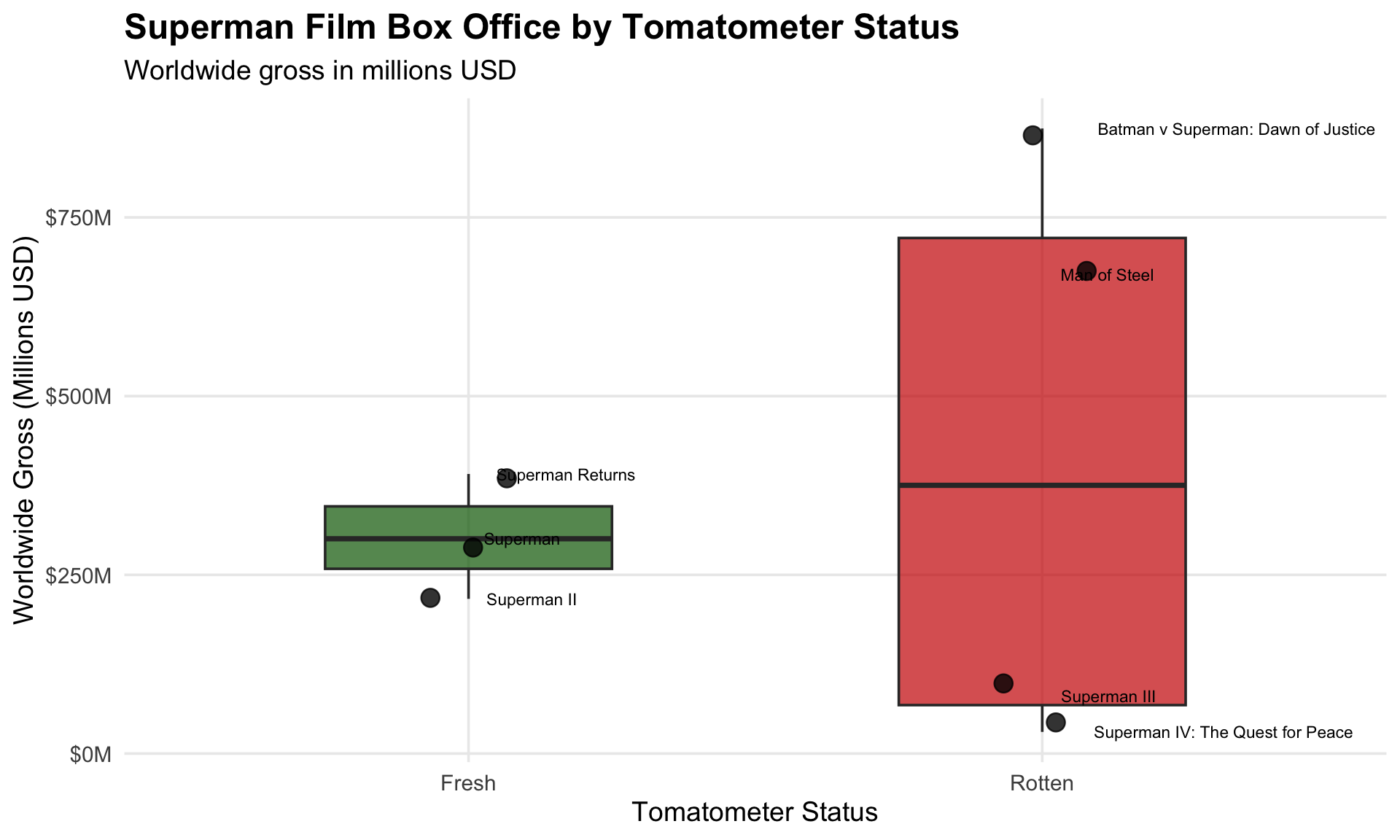
Box Office by Tomatometer Status
superman_combined |>
filter(!is.na(worldwide_gross) & !is.na(tomatometer)) |>
ggplot(aes(x = tomatometer, y = worldwide_gross, fill = tomatometer)) +
geom_boxplot(alpha = 0.7, width = 0.5) +
geom_jitter(width = 0.1, size = 4, alpha = 0.8) +
geom_text(
aes(label = title),
hjust = -0.2,
size = 3
) +
scale_fill_manual(
values = c("Fresh" = "darkgreen", "Rotten" = "red3")
) +
scale_y_continuous(labels = label_dollar(scale = 1, suffix = "M")) +
labs(
title = "Superman Film Box Office by Tomatometer Status",
subtitle = "Worldwide gross in millions USD",
x = "Tomatometer Status",
y = "Worldwide Gross (Millions USD)",
fill = "Status"
) +
theme_minimal(base_size = 14) +
theme(
legend.position = "none",
plot.title = element_text(face = "bold", size = 18),
panel.grid.minor = element_blank()
) +
coord_cartesian(clip = "off")